Reporte de pruebas en nodo de cálculo Dell R7525
Información del reporte:
Licencia Creative Commons

El contenido de los textos es responsabilidad de los autores y no refleja forzosamente el punto de vista de los dictaminadores, o de los miembros del Comité Editorial, o la postura del editor y la editorial de la publicación.
Para citar este reporte técnico:
Álvarez Castillo, I. C. (2025). Reporte de pruebas en nodo de cálculo Dell R7525. Cuadernos Técnicos Universitarios de la DGTIC, 3 (1). https://doi.org/10.22201/dgtic.ctud.2025.3.1.95
Irving Carlos Álvarez Castillo
Dirección General de Cómputo y de
Tecnologías de Información y Comunicación
Universidad Nacional Autónoma de México
ORCID: 0009-0001-7387-1689
Resumen:
Ante el cambio constante en la arquitectura de procesadores que son utilizados en las supercomputadoras, es necesario contar con información que permita conocer el comportamiento de los procesadores en diversas cargas de trabajo. Se evaluó un procesador AMD Epyc 7713 mediante estudios de escalabilidad ante cargas específicas de los códigos Gromacs y Quantum Espresso. Las aceleraciones y eficiencias obtenidas permiten conocer la escalabilidad que proporciona un nodo de cálculo con 128 núcleos de procesamiento en diferentes cargas de trabajo de High Performance Computing (HPC).
Palabras clave:
Supercomputadora, cómputo de alto rendimiento, AMD, evaluación de rendimiento, tiempos de ejecución, aceleración, eficiencia, Gromacs, Quantum Espresso.
1. Introducción
Una supercomputadora es una máquina compuesta por diversos sistemas de cómputo, almacenamiento e interconexión; ejemplo de una supercomputadora y los diversos sistemas que la integran se pueden consultar en la sección de Miztli de la página del departamento de Supercómputo (Departamento de Supercómputo, DGTIC. UNAM, https://www.super.unam.mx/Miztli). El uso de las supercomputadoras ha permitido ayudar a resolver y entender diferentes problemas de diversas áreas de la ciencia como química, física e ingeniería.
El sistema de cómputo de una supercomputadora es un sistema importante porque en él se realizan los cálculos asociados a las diferentes áreas científicas. Éste está integrado por una gran cantidad (cientos o miles) de nodos de cálculo, donde cada nodo uno está compuesto de procesadores, memoria principal (RAM) y almacenamiento secundario.
Los procesadores han tenido diversos cambios tecnológicos durante la última década (Guest et al., 2021, pp. 196–199), (Suggs et al., 2020), como el aumento en la cantidad de núcleos en cada procesador (Kolpakov & Posypkin, 2020, p. 2211). En el “TOP500”(TOP500, https://top5000.org/), se pueden consultar las características de las supercomputadoras y de sus procesadores desde junio de 1993.
Miztli es una supercomputadora que ha servido en la generación de cientos de artículos académicos para la Universidad Nacional Autónoma de México y, en 2024, cumple doce años en operación. Su antecesora, la supercomputadora Kanbalam, estuvo en operación 6 años (2006 a 2012) y, en el mundo. los períodos de actualización de las supercomputadoras son de alrededor de 5 años. Dado lo anterior y considerando que es complicado obtener refacciones de esta infraestructura, la Dirección General de Cómputo y de Tecnologías de Información y Comunicación (DGTIC) ha contemplado la adquisición de una nueva supercomputadora.
Para el proceso de adquisición de esta nueva supercomputadora es importante contar con información de los procesadores para conocer su comportamiento, sus ventajas y desventajas ante determinadas cargas de trabajo. Esta información podrá ser útil en la toma de decisiones del proyecto de adquisición de una nueva supercomputadora.
El objetivo del presente reporte es evaluar el comportamiento de procesadores AMD en un nodo de cálculo ante diversos tipos de carga de trabajo.
2. Desarrollo técnico
2.1 Metodología
En septiembre de 2023, se realizaron pruebas en un nodo de cálculo proporcionado por Dell modelo R7525, el cual contó con las siguientes características:
- 2 procesadores AMD EPYC 7713
- 128 núcleos de procesamiento
- 512 GB de RAM
Cada procesador AMD EPYC 7713 cuenta con 64 núcleos de procesamiento.
En el nodo de cálculo se le instaló el sistema operativo Rocky Linux versión 9.2 (versión del kernel 5.14) y se le deshabilitó el Hyper-Threading.
Las pruebas consistieron en realizar un estudio de escalabilidad utilizando dos códigos numéricos. Éste constó en ejecutar un mismo cálculo con una cantidad variable de núcleos de procesamiento; la ejecución de un caso en particular utilizando cierta cantidad de dichos núcleos fue repetida al menos cinco veces. El estudio es similar al desarrollado por Saini en “Performance Evaluation of a Supercomputer Based on AMD Rome and Intel Cascade Lake Processors” (Saini et al., 2022), añadiendo la variante en la cual, en lugar de utilizar comparativas de rendimiento (benchmarks), se utilizaron cálculos propios de algunos usuarios de la supercomputadora Miztli. Para la realización de estos cálculos, se implementaron las siguientes aplicaciones en el nodo de cálculo:
- Gromacs versión 2021.6
- Quantum Espresso versión 6.2.1
La finalidad de la implementación de ambas aplicaciones fue observar el comportamiento de los cálculos en este nodo de cálculo en particular, además de que las dos son ampliamente utilizadas en la supercomputadora Miztli.
Gromacs fue configurada utilizando el compilador GCC versión 11, la biblioteca OpenMPI versión 4 y la biblioteca FFTW versión 3.3.10.Tanto Gromacs como la biblioteca FFTW fueron construidas desde el código fuente. La entrada que se ejecutó para este código tiene 92,500 átomos y 150,000 pasos de integración.
Quantum Espresso fue construido utilizando el compilador de GCC versión 11 y la biblioteca OpenMPI versión 4. Se utilizó la biblioteca numérica Netlib proporcionada por el mismo software. Las entradas o casos utilizados para la aplicación Quantum Espresso tienen 16, 32, 48 y 64 átomos.
Se realizaron gráficas de tiempos, de aceleración y eficiencia, que se presentan en la sección de resultados. Las gráficas de aceleración y eficiencia permiten conocer qué tan eficientemente son utilizados los recursos computacionales (núcleos de procesamiento); los tiempos reportados miden el tiempo desde el inicio del cálculo hasta el final del mismo, es decir, se mide el tiempo de pared de cada cálculo. En las gráficas, una línea gris muestra el valor teórico ideal para la aceleración y la eficiencia.
3. Resultados
Análisis de los resultados de Gromacs
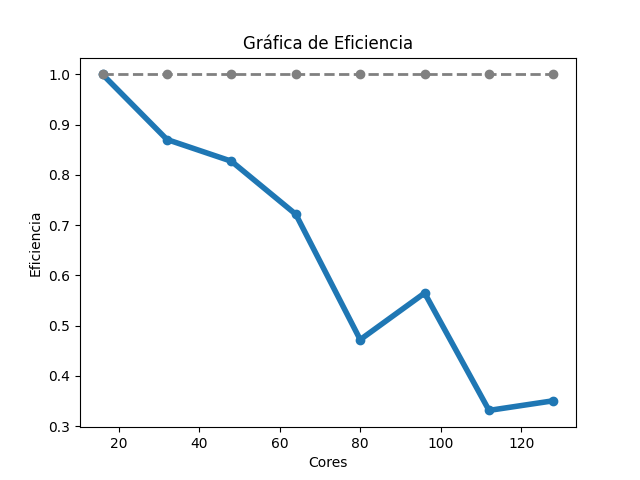
Para el caso del código Gromacs, la gráfica de tiempos (Imagen 1) muestra que, al aumentar la cantidad de núcleos de procesamiento, fue disminuyendo gradualmente el tiempo de ejecución. En la gráfica de aceleración (Imagen 2), la tasa máxima de cambio obtenida fue 3.39 al utilizar 96 núcleos de procesamiento, para esa misma cantidad de núcleos, la aceleración teórica es de 6; para 128, la aceleración obtenida fue de 2.8 y la aceleración teórica es de 8. Sobre la gráfica de eficiencia (Imagen 3), se obtienen resultados mayores a 80% al utilizar 16, 32 y 48 núcleos de procesamiento, también se muestra que, conforme se utiliza una mayor cantidad de éstos, disminuye la eficiencia.
Las imágenes 1, 2 y 3 muestran las gráficas de tiempos, aceleración y eficiencia obtenidas (basadas en los datos de las tablas 1, 2 y 3 respectivamente del Anexo A) al ejecutar una entrada de Gromacs en diferentes cantidades de núcleos de procesamiento:
Imagen 1
Gráfica de tiempos de Gromacs
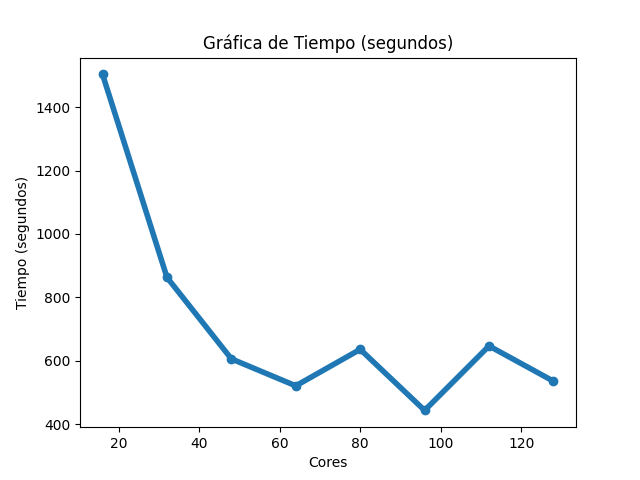
Imagen 2
Gráfica de aceleración de Gromacs
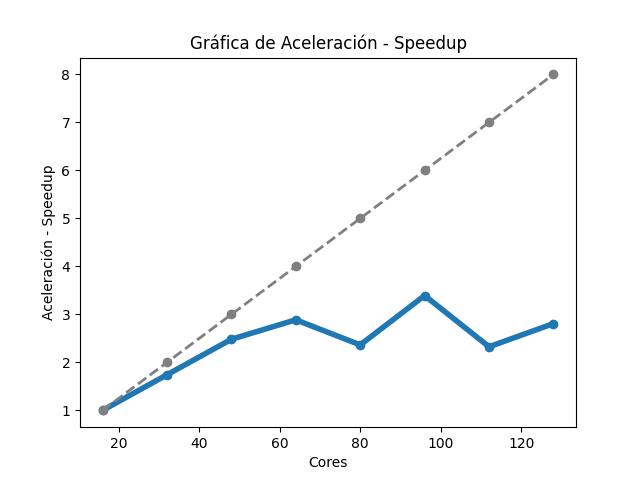
Imagen 3
Gráfica de eficiencia de Gromacs
Resultados de Quantum Espresso
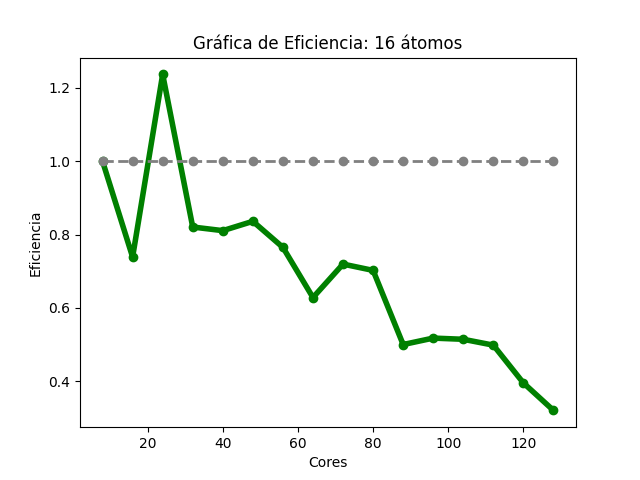
Para el caso del código Quantum Espresso de 16 átomos: la gráfica de tiempos (Imagen 4) muestra que, al aumentar la cantidad de núcleos de procesamiento, fue disminuyendo gradualmente el tiempo de ejecución. En la gráfica de aceleración (Imagen 5), la tasa máxima de cambio obtenida fue 7.02 con 80 núcleos de procesamiento, para esa misma cantidad de núcleos, la aceleración teórica es de 10; para 128, la aceleración obtenida es 5.12 y la aceleración teórica es de 16. El la gráfica de eficiencia (Imagen 6), se obtienen resultados mayores a 80% al utilizar 8, 24, 32, 40 y 48 núcleos de procesamiento, también se observó que, conforme se utiliza una mayor cantidad de éstos , disminuye la eficiencia.
Las imágenes 4, 5 y 6 muestran las gráficas de tiempos, aceleración y eficiencia obtenidas (basadas en los datos de las tablas 4, 5 y 6 respectivamente del Anexo A) al ejecutar una entrada de 16 átomos de Quantum Espresso en diferentes cantidades de núcleos de procesamiento:
Imagen 4
Gráfica de tiempos de Quantum Espresso
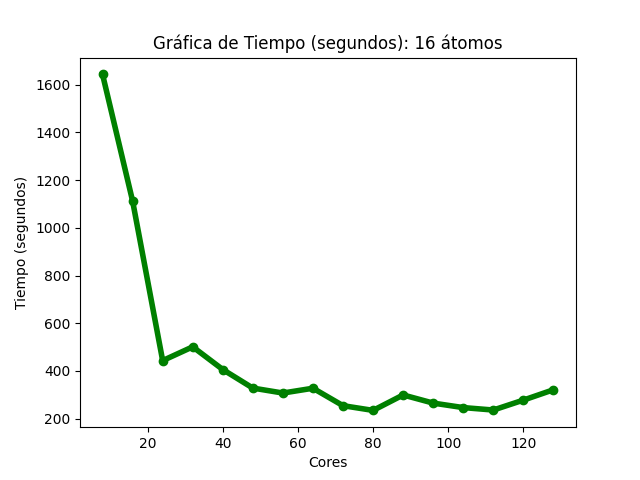
Imagen 5
Gráfica de aceleración de Quantum Espresso
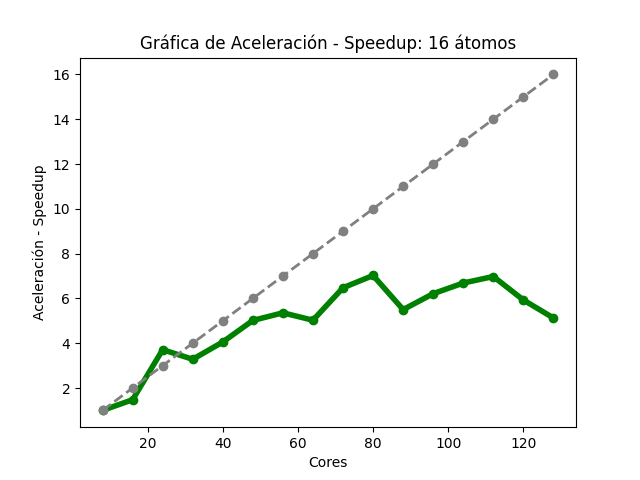
Imagen 6
Gráfica de eficiencia de Quantum Espresso
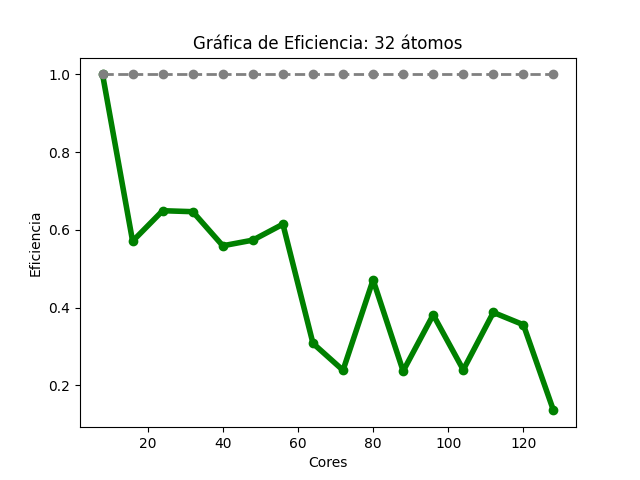
Para el caso del código Quantum Espresso (32 átomos), al aumentar la cantidad de núcleos de procesamiento, fue disminuyendo el tiempo de ejecución (Imagen 7) y se observan algunas variaciones en 64, 72, 88, 104 y 128 núcleos . En la gráfica de aceleración (Imagen 8), la tasa máxima de cambio fue 5.42, utilizando 112 núcleos de procesamiento, para esa cantidad , la aceleración teórica es de 14; en 128, la aceleración obtenida fue de 2.16 y su aceleración teórica es de 16. En la gráfica de eficiencia (Imagen 9, se obtienen resultados mayores al 80% al utilizar solo 8 núcleos de procesamiento, también se observa que, conforme se utiliza una mayor cantidad de éstos, disminuye la eficiencia.
Las imágenes 7, 8 y 9 muestran las gráficas de tiempos, aceleración y eficiencia obtenidas (basadas en los datos de las tablas 7, 8 y 9 respectivamente del Anexo A) al ejecutar una entrada de 32 átomos de Quantum Espresso en diferentes cantidades de núcleos de procesamiento:
Imagen 7
Gráfica de tiempos del cálculo II de Quantum Espresso
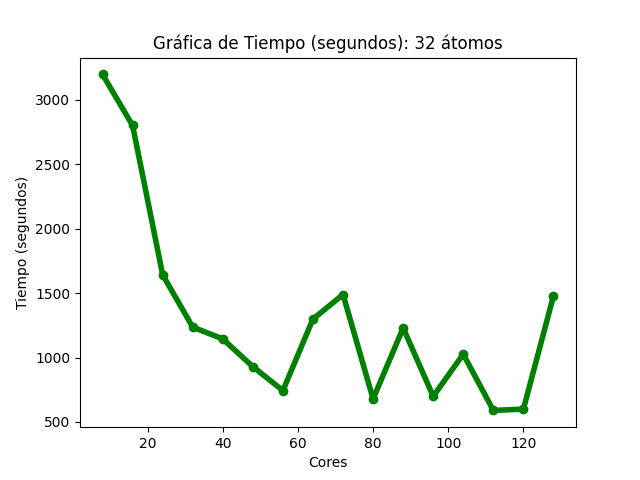
Imagen 8
Gráfica de aceleración del cálculo II de Quantum Espresso
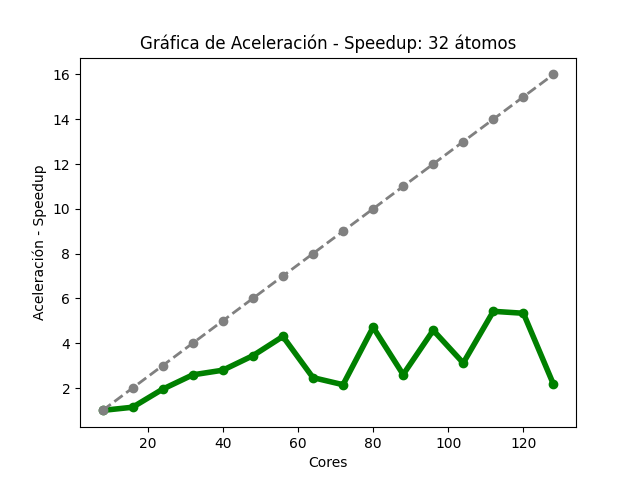
Imagen 9
Gráfica de eficiencia del cálculo II de Quantum Espresso
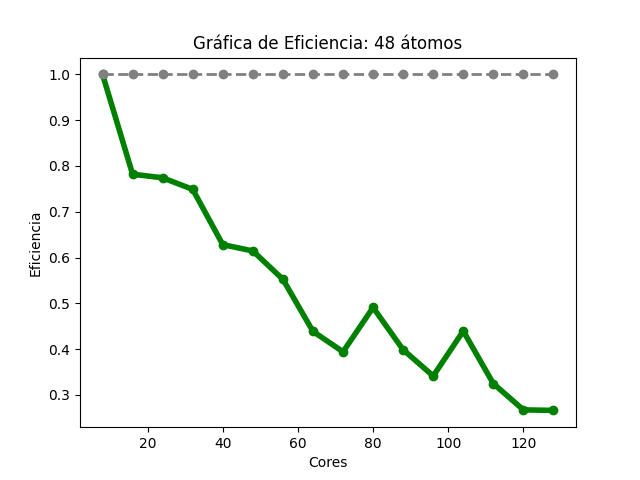
Para el caso del código Quantum Espresso (48 átomos), se observó que, al aumentar la cantidad de núcleos de procesamiento, fue disminuyendo gradualmente el tiempo de ejecución (Imagen 10). En la gráfica de aceleración (Imagen 11), la tasa máxima de cambio fue 5.71, obtenida con 104 núcleos , para esa misma cantidad de éstos, la aceleración teórica esperada es 13; en 128, la aceleración obtenida fue de 4.25 y la aceleración teórica esperada es de 16. En la gráfica de eficiencia (Imagen 12), se obtienen resultados mayores a 80% al utilizar solo 8 núcleos, también se observa que, conforme se utiliza una mayor cantidad de éstos, disminuye la eficiencia.
Las imágenes 10, 11 y 12 muestran las gráficas de tiempos, aceleración y eficiencia obtenidas (basadas en los datos de las tablas 10, 11 y 12 respectivamente del Anexo A) al ejecutar una entrada de 48 átomos de Quantum Espresso en diferentes cantidades de núcleos de procesamiento:
Imagen 10
Gráfica de tiempos del cálculo III de Quantum Espresso
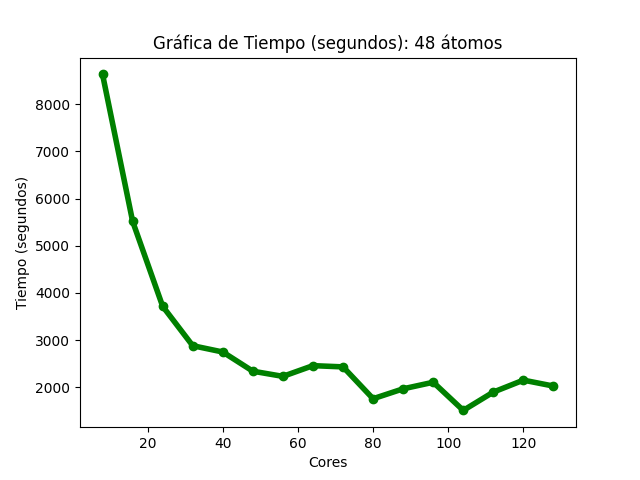
Imagen 11
Gráfica de aceleración del cálculo III de Quantum Espresso
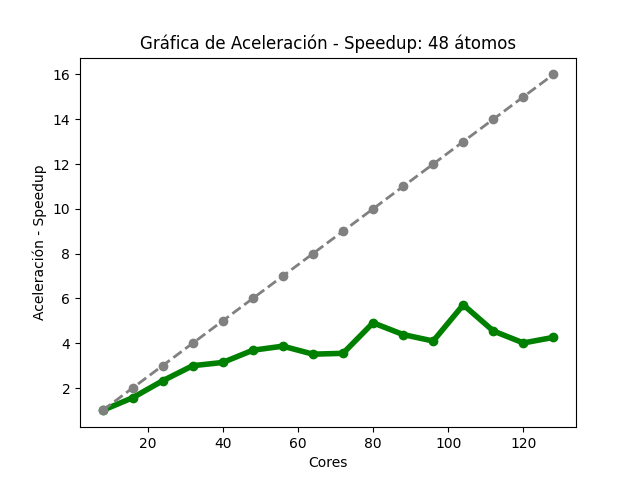
Imagen 12
Gráfica de eficiencia del cálculo III de Quantum Espresso
Para el caso del código Quantum Espresso (64 átomos), se observó que, al aumentar la cantidad de núcleos de procesamiento, fue disminuyendo gradualmente el tiempo de ejecución (Imagen 13). En la gráfica de aceleración (Imagen 14), la tasa máxima de cambio fue 4.99, obtenida con 112 núcleos , para esa misma cantidad de éstos la aceleración teórica esperada es 6; en 128, la aceleración obtenida fue de 3.11 y la aceleración teórica esperada es de 8. Sobre la gráfica de eficiencia (Imagen 15), se obtienen resultados mayores a 80% al utilizar só lo 16, 32, 48 y 64 núcleos, también se observa que, conforme se utiliza una mayor cantidad de éstos, la eficiencia disminuye.
Las imágenes 13, 14 y 15 muestran las gráficas de tiempos, aceleración y eficiencia obtenidas (basadas en los datos de las tablas 13, 14 y 15 respectivamente del Anexo A) al ejecutar una entrada de 64 átomos de Quantum Espresso en diferentes cantidades de núcleos de procesamiento:
Imagen 13
Gráfica de tiempos del cálculo IV de Quantum Espresso
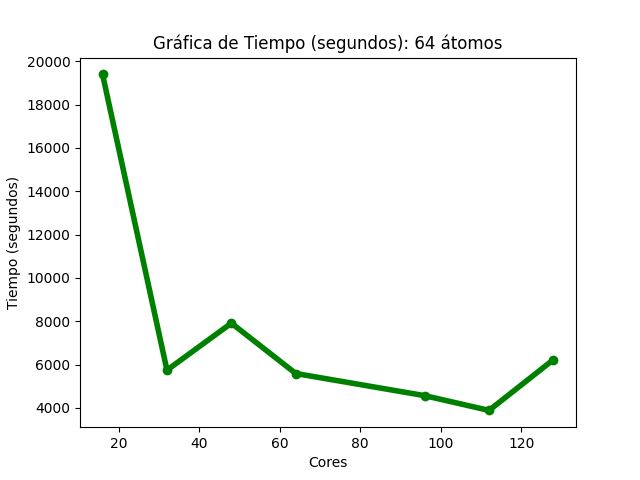
Imagen 14
Gráfica de aceleración del cálculo IV de Quantum Espresso
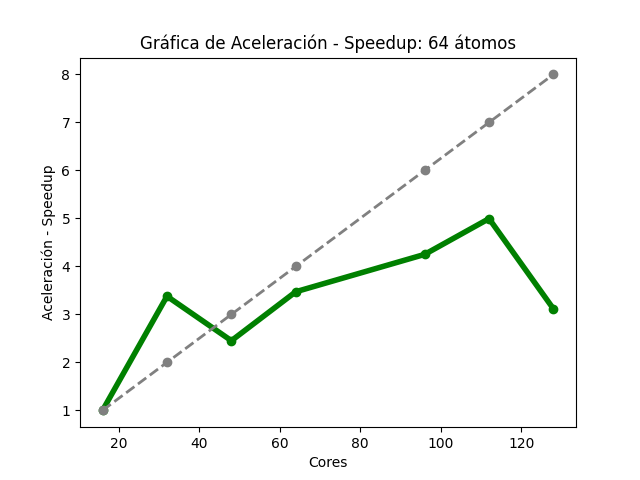
Imagen 15
Gráfica de eficiencia del cálculo IV de Quantum Espresso
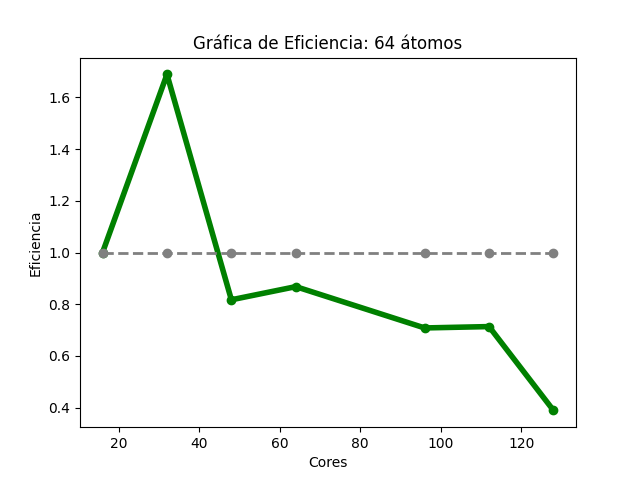
4. Conclusiones
Dependiendo de la cantidad de núcleos de procesamiento utilizados las gráficas de aceleración y eficiencia se mantienen cerca del valor teórico los siguientes tres casos:
- Gromacs
- Quantum Espresso (caso 16 átomos)
- Quantum Espresso (caso 64 átomos)
Específicamente, para 1) y 2), las aceleraciones y eficiencias se mantienen cerca del teórico hasta 48 núcleos de procesamiento; al aumentar una cantidad mayor de núcleos, las aceleraciones y eficiencias de ambos casos se alejan del teórico. Por otro lado, para el caso 3), la aceleración y eficiencia se mantiene cerca del teórico hasta 64 núcleos de procesamiento y, al incrementar un mayor número de núcleos, la aceleración y eficiencia se distancia de la referencia teórica.
Al realizar las pruebas tanto del código Gromacs como el de Quantum Espresso, se observó que la distribución de los núcleos de procesamiento no fue secuencial, es decir, si un cálculo requería utilizar 64 núcleos, no se asignaban del núcleo 0 al 63, se distribuían 32 en un procesador y los otros 32 en otro.
Al realizar un cálculo con cierta cantidad de núcleos de procesamiento, se utilizó el nodo de cálculo de forma dedicada, es decir, no se realizaron otros cálculos aun habiendo disponibilidad de núcleos.
En el análisis de los resultados, se puede observar que hay un escalamiento limitado (las aceleraciones y eficiencias obtenidas son cercanas al teórico al utilizar pocos núcleos de procesamiento y son distantes del teórico al utilizar la totalidad de los núcleos del nodo de cálculo) para las cargas de trabajo probadas en este procesador. Se recomienda realizar más pruebas en diferentes configuraciones tanto de hardware (procesadores con menor cantidad de núcleos de procesamiento) como de software (suites de desarrollo) para contar con información suficiente en cuanto a los procesadores AMD.
La información obtenida nos permitió evaluar el comportamiento del procesador AMD en un nodo de cálculo con varios tipos de cargas de trabajo, por lo anterior, se cumplió con el objetivo de este trabajo.
Agradecimientos
Se agradece a la empresa DELL por el nodo de cálculo prestado para la realización de pruebas. Se agradece a S. Frausto, E. Ortega y A. Aparicio del departamento de Supercómputo de la DGTIC por el apoyo brindado para la realización de este reporte.
Referencias
Departamento de Supercómputo, DGTIC. UNAM. (n.d.). Supercomputadora Miztli. Retrieved November 15, 2024, from https://www.super.unam.mx/miztli
DGTIC. (n.d.). Retrieved November 15, 2024, from https://www.tic.unam.mx/
Guest, M. F., Elena, A. M., & Chalk, A. B. G. (2021). DL_POLY - A performance overview analysing, understanding and exploiting available HPC technology. Molecular Simulation, 47(2–3), 194–227. Scopus®. https://doi.org/10.1080/08927022.2019.1603380
Kolpakov, R., & Posypkin, M. (2020). The scalability analysis of a parallel tree search algorithm. Optimization Letters, 14(8), 2211–2226. Scopus®. https://doi.org/10.1007/s11590-020-01547-6
Saini, S., Baron, J., Chang, J., Hood, R., & Jin, H. (2022). Performance Evaluation of a Supercomputer Based on AMD Rome and Intel Cascade Lake Processors. 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2022 IEEE International, IPDPSW, 848–859. IEEE Xplore Digital Library. https://doi.org/10.1109/IPDPSW55747.2022.00141
Suggs, D., Subramony, M., & Bouvier, D. (2020). The AMD “Zen 2” Processor. IEEE Micro, Micro, IEEE, 40(2), 45–52. IEEE Xplore Digital Library. https://doi.org/10.1109/MM.2020.2974217
Top 500. (https://top500.org/). Retrieved November 15, 2024, from https://top500.org/lists/top500/
Anexos
Anexo A. Tablas
Tabla 1
Tabla de tiempos de Gromacs
| Núcleos | Tiempo (segundos) |
| 16 | 1503.29 |
| 32 | 862.832 |
| 48 | 605.71 |
| 64 | 520.64 |
| 80 | 635.675 |
| 96 | 443.109 |
| 112 | 646.451 |
| 128 | 535.222 |
Tabla 2
Tabla de aceleración de Gromacs
| Núcleos | Aceleración (Speedup) |
| 16 | 1 |
| 32 | 1.7422 |
| 48 | 2.4818 |
| 64 | 2.8873 |
| 80 | 2.3648 |
| 96 | 3.3925 |
| 112 | 2.3254 |
| 128 | 2.8087 |
Tabla 3
Tabla de eficiencia de Gromacs
| Núcleos | Eficiencia |
| 16 | 1 |
| 32 | 0.8704 |
| 48 | 0.8272 |
| 64 | 0.7216 |
| 80 | 0.472 |
| 96 | 0.5648 |
| 112 | 0.3312 |
| 128 | 0.3504 |
Tabla 4
Tabla de tiempos de Quantum Espresso
| Núcleos | Tiempo (segundos) |
| 8 | 1643.75 |
| 16 | 1112.54 |
| 24 | 442.956 |
| 32 | 500.78 |
| 40 | 405.502 |
| 48 | 327.65 |
| 56 | 306.906 |
| 64 | 327.062 |
| 72 | 253.852 |
| 80 | 234.058 |
| 88 | 298.842 |
| 96 | 264.642 |
| 104 | 245.834 |
| 112 | 235.594 |
| 120 | 277.258 |
| 128 | 320.682 |
Tabla 5
Tabla de aceleración de Quantum Espresso
| Núcleos | Aceleración (Speedup) |
| 8 | 1 |
| 16 | 1.47747 |
| 24 | 3.71087 |
| 32 | 3.28238 |
| 40 | 4.05362 |
| 48 | 5.01679 |
| 56 | 5.35588 |
| 64 | 5.02581 |
| 72 | 6.47524 |
| 80 | 7.02284 |
| 88 | 5.5004 |
| 96 | 6.21123 |
| 104 | 6.68643 |
| 112 | 6.97705 |
| 120 | 5.9286 |
| 128 | 5.1258 |
Tabla 6
Tabla de eficiencia de Quantum Espresso
| Núcleos | Eficiencia |
| 8 | 1 |
| 16 | 0.738737 |
| 24 | 1.23696 |
| 32 | 0.820596 |
| 40 | 0.810724 |
| 48 | 0.836132 |
| 56 | 0.765126 |
| 64 | 0.628226 |
| 72 | 0.719471 |
| 80 | 0.702284 |
| 88 | 0.500037 |
| 96 | 0.517602 |
| 104 | 0.514341 |
| 112 | 0.498361 |
| 120 | 0.39524 |
| 128 | 0.320363 |
Tabla 7
Tabla de tiempos del cálculo II de Quantum Espresso
| Núcleos | Tiempo (segundos) |
| 8 | 3198.46 |
| 16 | 2801.77 |
| 24 | 1642.22 |
| 32 | 1236.44 |
| 40 | 1144.38 |
| 48 | 929.498 |
| 56 | 743.606 |
| 64 | 1298.8 |
| 72 | 1489.39 |
| 80 | 678.892 |
| 88 | 1229.82 |
| 96 | 698.916 |
| 104 | 1026.23 |
| 112 | 589.746 |
| 120 | 599.358 |
| 128 | 1477.45 |
Tabla 8
Tabla de aceleración del cálculo II de Quantum Espresso
| Núcleos | Aceleración (Speedup) |
| 8 | 1 |
| 16 | 1.14159 |
| 24 | 1.94764 |
| 32 | 2.58682 |
| 40 | 2.79492 |
| 48 | 3.44106 |
| 56 | 4.30128 |
| 64 | 2.46262 |
| 72 | 2.1475 |
| 80 | 4.71129 |
| 88 | 2.60075 |
| 96 | 4.57632 |
| 104 | 3.11671 |
| 112 | 5.42345 |
| 120 | 5.33648 |
| 128 | 2.16486 |
Tabla 9
Tabla de eficiencia del cálculo II de Quantum Espresso
| Núcleos | Eficiencia |
| 8 | 1 |
| 16 | 0.570794 |
| 24 | 0.649214 |
| 32 | 0.646705 |
| 40 | 0.558985 |
| 48 | 0.57351 |
| 56 | 0.614469 |
| 64 | 0.307827 |
| 72 | 0.238611 |
| 80 | 0.471129 |
| 88 | 0.236431 |
| 96 | 0.38136 |
| 104 | 0.239747 |
| 112 | 0.38739 |
| 120 | 0.355765 |
| 128 | 0.135304 |
Tabla 10
Tabla de tiempos del cálculo III de Quantum Espresso
| Núcleos | Tiempo (segundos) |
| 8 | 8632.4 |
| 16 | 5519.4 |
| 24 | 3716.8 |
| 32 | 2881.87 |
| 40 | 2748.33 |
| 48 | 2341.46 |
| 56 | 2232.04 |
| 64 | 2459.25 |
| 72 | 2433.06 |
| 80 | 1758.26 |
| 88 | 1968.25 |
| 96 | 2107.33 |
| 104 | 1510.73 |
| 112 | 1898.77 |
| 120 | 2152.01 |
| 128 | 2026.51 |
Tabla 11
Tabla de aceleración del cálculo III de Quantum Espresso
| Núcleos | Aceleración (Speedup) |
| 8 | 1 |
| 16 | 1.56401 |
| 24 | 2.32254 |
| 32 | 2.99542 |
| 40 | 3.14096 |
| 48 | 3.68676 |
| 56 | 3.86749 |
| 64 | 3.51018 |
| 80 | 4.90964 |
| 88 | 4.38583 |
| 96 | 4.09638 |
| 104 | 5.71406 |
| 112 | 4.54632 |
| 120 | 4.01132 |
| 128 | 4.25974 |
Tabla 12
Tabla de eficiencia del cálculo III de Quantum Espresso
| Núcleos | Eficiencia |
| 8 | 1 |
| 16 | 0.782005 |
| 24 | 0.774179 |
| 32 | 0.748855 |
| 40 | 0.628191 |
| 48 | 0.61446 |
| 56 | 0.552499 |
| 64 | 0.438772 |
| 72 | 0.394217 |
| 80 | 0.490964 |
| 88 | 0.398712 |
| 96 | 0.341365 |
| 104 | 0.439543 |
| 112 | 0.324737 |
| 120 | 0.267421 |
| 128 | 0.266234 |
Tabla 13
Tabla de tiempos del cálculo IV de Quantum Espresso
| Núcleos | Tiempo (segundos) |
| 16 | 19391.4 |
| 32 | 5740 |
| 48 | 7909.2 |
| 64 | 5584.6 |
| 96 | 4562.8 |
| 112 | 3882 |
| 128 | 6225.8 |
Tabla 14
Tabla de aceleración del cálculo IV de Quantum Espresso
| Núcleos | Aceleración (Speedup) |
| 16 | 1 |
| 32 | 3.37829 |
| 48 | 2.45175 |
| 64 | 3.4723 |
| 96 | 4.24989 |
| 112 | 4.99521 |
| 128 | 3.11468 |
Tabla 15
Tabla de eficiencia del cálculo IV de Quantum Espresso
| Núcleos | Eficiencia |
| 16 | 1 |
| 32 | 1.68915 |
| 48 | 0.817251 |
| 64 | 0.868075 |
| 96 | 0.708315 |
| 112 | 0.713601 |
| 128 | 0.389336 |